
Kapitel 1. Einführung
Dieser Artikel enthält eine Schritt-für-Schritt-Anleitung, die Ihnen die Entwicklung eigener Anwendungen zum Maschinellen Lernen (ML) mit dem System on Module von Variscite erläutert. Es wird gezeigt, wie man ein Image mit dem Yocto Linux BSP und einer Sammlung von Entwicklungstools, Dienstprogrammen und Bibliotheken zur Erstellung von ML-Anwendungen aus der NXP eIQ™ ML Software Development Environment entwickelt, wie man die mit dem Image erzeugten Standardbeispiele ausführt und wie man schließlich ein einfaches ML-Beispiel von Grund auf schreibt.
1.1. eIQ™ Software-Entwicklungsumgebung für maschinelles Lernen – Überblick
Mit eIQ™ können Benutzer mühelos eine vollständige Anwendung auf Systemebene entwickeln, die zur Lösung von ML-Problemen im Zusammenhang mit Bild-, Audio-, Zeitseriendaten usw. dient. Gängige Beispiele sind Gesichtserkennung, Posenschätzung, Gestenerkennung, Interpretation von Sprachakzenten usw.
Der neueste Software-Stack von eIQ™ umfasst ein ML-Workflow-Tool unter der Bezeichnung eIQ™ Toolkit, mit dem Sie mehr zu ML erfahren und Ihr eigenes ML-Modell über das eIQ-Portal trainieren können. Darüber hinaus enthält es eIQ™ Inference , das Unterstützung für Inferenz-Engines, neuronale Netzwerk-Compiler und optimierte Bibliotheken wie TensorFlow Lite, Arm NN, ONNX Runtime, PyTorch, OpenCV und DeepViewRT bietet.
Weitere Informationen über eIQ™ finden Sie unter:
1.2. Voraussetzungen
1.2.1 Unterstützte Variscite SoM
Die DART-MX8M-PLUS und VAR-SOM-MX8M-PLUS beruhen auf dem NXP i.MX 8M Plus Prozessor, der eine Neural Processing Unit (NPU) enthält, d. h. einen speziellen AI/ML-Beschleuniger. Die NPU trägt zur Erzielung hoher Leistung während des Inferenzprozesses von ML-Anwendungen bei.
Obwohl dieser Artikel sich auf Module bezieht, die auf dem i.MX 8M Plus Prozessor basieren, können andere Module, die auf den NXP i.MX 8- und i.MX 8M-Familien aufbauen, ebenfalls für ML-Anwendungen verwendet werden. In solchen Fällen wird die GPU oder CPU anstelle der NPU für den Inferenzprozess verwendet.
1.2.2. Yocto Linux BSP mit eIQ™ Enablement
So erstellen Sie ein Bild mit den eIQ™-Inferenzmaschinen und -Bibliotheken:
1. Folgen Sie den Abschnitten 1 und 3 in der entsprechenden Anleitung „Yoctoaus dem Quellcode erstellen“ auf variwiki.com , um Ihren Build-Host einzurichten und die Yocto-Quellenfür das SOM und die gewünschte Yocto-Version abzurufen.
Zum Beispiel:
https://variwiki.com/index.php?title=Yocto_Build_Release&release=RELEASE_HARDKNOTT_V1.0_DART-MX8M-PLUS
…
$ repo init -u https://github.com/varigit/variscite-bsp-platform.git -b <tag_name> -m <manifest_name> ①
$ repo sync -j$(nproc) ②
❶ E.g., replace <tag_name> with fsl-hardknott; <manifest_name> with imx-5.10.35-2.0.0-var01.xml
❷ Der Schritt zur Repo-Sync kann eine Weile dauern ☕
2. Bereiten Sie die Umgebung vor, um das Image für das gewählte Modul zu erstellen:
$ MACHINE=<module_name> DISTRO=fsl-imx-xwayland . var-setup-release.sh -b build_xwayland ①❶ E.g., replace <module_name> with imx8mp-var-dart
3. Verwenden Sie das imx-image-full Image, um die eIQ™ ML-Pakete zu erstellen:
$ bitbake imx-image-full ①❶ Dieser Schritt kann je nach den Spezifikationen Ihres Computers mehrere Stunden in Anspruch nehmen ☕
4. Flashen Sie das vollständige Image auf die SD-Karte:
- Das erstellte Image finden Sie in folgendem Ordner:
🗀 ${BUILD}/tmp/deploy/images/<module_name>
$ zcat imx-image-full-<module_name>.wic.gz | sudo dd of=/dev/sd<x> bs=1M status=progress conv=fsync ①❶E.g., replace <module_name> with imx8mp-var-dart; <x> with b
⚠️ VORSICHT!Verwenden Sie die Befehle dmesg oder lsblk , um den korrekten Gerätenamen der SD-Karte zu überprüfen.

VAR-SOM-MX8M-PLUS System on Module
Kapitel 2. eIQ™-Standardanwendungen für Maschinelles Lernen
Aufgrund der Vielzahl von ML-Unterkategorien wird in diesem Artikel nur ein Beispiel aus der Unterkategorie des Überwachten Lernens behandelt, nämlich das Problem der Bildklassifizierung . Um die Funktionsweise des Klassifizierungsproblems zu verstehen, führen wir ein eIQ™-Beispiel aus, das ein trainiertes Einstiegsmodell von TensorFlow und die mit dem Yocto Linux BSP erstellte Inferenzmaschine von TensorFlow Lite verwendet.
2.1.TensorFlow Lite
Die beliebteste und am besten unterstützte Inferenzmaschine und Bibliothek von eIQ™ ist das von Google entwickelte TensorFlow Lite. Während TensorFlow eine beliebte Open-Source-Plattform für maschinelles Lernen ist, die sowohl für Netzwerktraining als auch für Inferenzen verwendet werden kann, handelt es sich bei TensorFlow Lite um einen Werkzeugsatz, der speziell für die Konvertierung und Ausführung von Inferenzen aus TensorFlow-Modellen auf eingebetteten Geräten mit geringerer Latenz und kleinerer Binärgröße entwickelt wurde.
2.1.1 Überblick zur Bildklassifizierung
Die Bildklassifizierung gehört zu den Klassifizierungsproblemen aus der Unterkategorie „Überwachtes Lernen“, mit denen man erkennen kann, was ein Bild darstellt, ohne sich auf fest kodierte Regeln zu stützen. Um dies zu erreichen, müssen wir zunächst ein Bildklassifizierungsmodell zur Erkennung verschiedener Klassen von Bildern trainieren. Wir können zum Beispiel ein Modell trainieren, das viele Objekte erkennt, wie Fahrzeuge, Menschen, Ampeln, Obstsorten, Tiere usw.
Für das Training eines Bildklassifizierungsmodells müssen die Bilder und die dazugehörigen Beschriftungen in das Training einfließen. Hierzu sind Hunderte oder Tausende von Bildern für jede Beschriftung erforderlich, damit das Modell auf effiziente Weise lernen kann, die Zugehörigkeit neuer Bilder zu den jeweiligen Klassen vorherzusagen, auf die es trainiert worden ist. Dieser Prozess, bei dem das Modell eine Vorhersage für ein neues Eingabebild trifft, wird Inferenz genannt.
Der Trainingsprozess eines neuen Modells nimmt viel Zeit in Anspruch und hängt von verschiedenen Aspekten ab, wie etwa der Definition des neuronalen Netzwerks und der zum Training des Modells herangezogenen Datenmenge.
Das in diesem Artikel verwendete Modell wurde zuvor mit TensorFlow trainiert und getestet. Wie im ersten Kapitel dieses Artikels erwähnt, können Sie über das NXP eIQ™-Portal auch Ihr eigenes ML-Modell erstellen, optimieren, debuggen, konvertieren und exportieren.
Wenn wir dem Modell ein neues Bild als Dateneingabe zur Verfügung stellen, gibt es die Wahrscheinlichkeit aus, dass das Bild jedes der Objekte repräsentiert, für die es trainiert wurde. Ein Beispiel für eine solche Ausgabe könnte wie folgt in Tabelle 1aussehen:
Tabelle 1. Beispiel für Wahrscheinlichkeiten
| Objektname (Beschriftung) | Wahrscheinlichkeit |
| Dog | 0.91 |
| Cat | 0.07 |
| Rabbit | 0.02 |
Das Bildklassifizierungsmodell wird mit der entsprechenden Beschriftungsdatei bereitgestellt, welche die Liste der Objekte enthält, auf die das Modell trainiert wurde (siehe z.B. tensorflow/lite/java/ovic/src/testdata/labels.txt im folgenden Beispiel- Quellcode). Jede Zahl in der Ausgabe entspricht einer Beschriftung in der Beschriftungsdatei. Im obigen Beispiel zeigt die Verknüpfung der Ausgabe mit den drei Bezeichnungen, auf die das Modell trainiert wurde, eine hohe Wahrscheinlichkeit, dass das Bild in diesem Fall einen Hund darstellt.
2.1.2. Beispiel für die Bildklassifizierung
Das mit den eIQ™-Paketen erstellte Vollbild enthält ein in C++ geschriebenes Beispiel für die Bildklassifizierung sowie ein ähnliches in Python geschriebenes Beispiel. In der C++ API von TensorFlow kann die Recheneinheit ausgewählt werden, auf der die Inferenz ausgeführt werden soll. In den Python-Bindungen gibt es diese Option nicht, weshalb die in Python geschriebenen Beispiele die Inferenz nur auf der NPU ausführen.
In diesem Abschnitt wird erklärt, wie Sie das in C++ geschriebene Standardbeispiel ausführen. Der nächste Abschnitt erläutert, wie das in Phyton geschriebene Standardbeispiel ausgeführt wird. Hier erfahren Sie, wie man ein Beispiel von Grund auf mit den Python-Bindungen von TensorFlow Lite schreibt.
Das Beispiel in C++ enthält bereits ein trainiertes Einstiegsmodell, eine Beschriftungsdatei und ein Bildbeispiel, das als Eingabe für den Inferenzprozess verwendet werden kann – siehe Tabelle 2 weiter unten:
Tabelle 2. Details zum Beispiel für die Bildklassifizierung
| Beispielname | Sprache | Standardmodell | Standardbeschriftungen | Standardeingabe |
| label_image | C++/Python | mobilenet_v1_1.0_224 _quant.tflite |
labels.txt | grace_hopper.bmp |
• Booten Sie das Board und wechseln Sie zum folgenden Ordner, in dem sich das Beispiel für die Bildklassifizierung befindet:
$ cd /usr/bin/tensorflow-lite-<version>/examples ①❶ E.g., replace <version> with 2.4.1
• Nutzen Sie folgende Argumente, um verschiedene Modell-/Beschriftungs-/ Bildeingabedateien zu verwenden:
$ ./label_image -m <model_file_name.tflite> -l <labels_file_name.txt> -i <image_file_name.extension>Wird kein Argument angegeben, verwendet das Beispiel die Standardargumente aus Tabelle 2.
Beispiel in C++ (CPU)
Führen Sie das Beispiel für das Beschriftungsbild aus, indem Sie das Argument „-a“ mit dem Wert „0“ verwenden, um die Inferenz auf der CPU auszuführen:
$ ./label_image -a 0- Das Ergebnis einer erfolgreichen Klassifizierung sollte in etwa wie folgt aussehen:
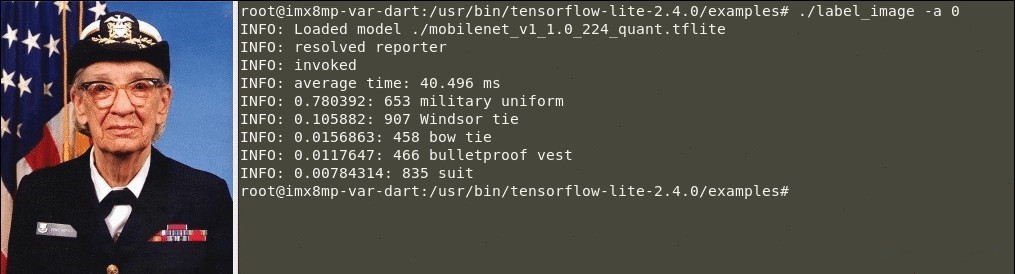
Abbildung 1. Beispiel für die Bildklassifizierung anhand der Ausführung von TensorFlow Lite (CPU-Inferenz)
🕒 Inferenzzeit auf der CPU: 40.496 Millisekunden.
Beispiel in C++ (NPU)
Führen Sie das Beispiel für das Beschriftungsbild aus, indem Sie das Argument „-a“ mit dem Wert „1“ verwenden, um die Inferenz auf der NPUauszuführen:
$ ./label_image -a 1- Das Ergebnis einer erfolgreichen Klassifizierung sollte in etwa wie folgt aussehen:
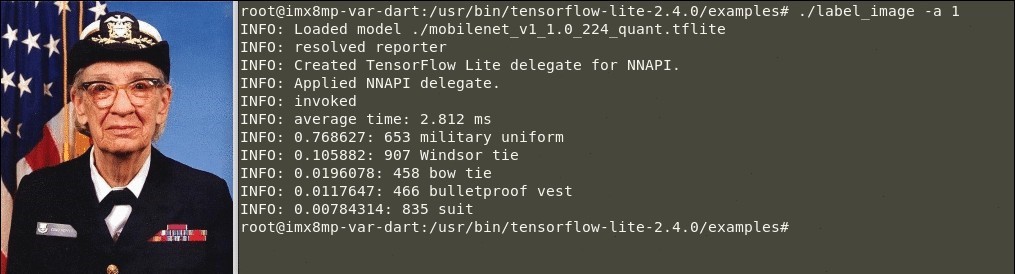
Abbildung 2. Beispiel für die Bildklassifizierung anhand der Ausführung von TensorFlow Lite (NPU-Inferenz)
🕒 Inferenzzeit auf NPU: 2.812 Millisekunden.
Diese Meldung zeigt an, dass die Inferenz auf NPU läuft:
“INFO: Applied NNAPI delegate.”
Der Quellcode für das label_image-Beispiel ist im tensorflow-imx Repository verfügbar:

DART-MX8M-PLUS System on Module
Kapitel 3. eIQ™ ML-Anwendungsentwicklung
Dieser Abschnitt ist eine Schritt-für-Schritt-Anleitung zur Entwicklung eines einfachen Bildklassifizierungsbeispiels anhand eines Einsteigermodells, einer Beschriftungsdatei und eines Bildes als Dateneingabe. Dieses Beispiel ist in Python geschrieben und verwendet die TensorFlow Lite Python API.
In den folgenden Schritten wird dargestellt, wie man das Bild öffnet und gemäß der Eingabegröße des Modells skaliert. Weiterhin wird gezeigt, wie das Bild als Eingabedaten durch den Inferenzprozess auf der NPU geladen wird und wie man schließlich die Ausgabe analysiert, um die Wahrscheinlichkeiten zu erhalten.
Der Quellcode für dieses Bildklassifizierungsbeispiel ist verfügbar unter:
Im oben genannten Repository finden Sie weitere Beispiele, wie:
Klassifizierung von Bild- und Videodateien sowie Echtzeit-Videostreams.
Erkennung von Bild- und Videodateien sowie von Echtzeit-Videostreams (welche die Klassifizierungsbezeichnung zusammen mit der Position des Objekts im Bild zurückgibt und ein Rechteck um das Objekt zeichnet).
Anwendung der Benutzeroberfläche, usw.
3.1. Bildklassifizierung von Anfang an
3.1.1. Erste Schritte
1. Erstellen Sie ein Verzeichnis und rufen Sie das Startermodell für die Bildklassifizierung sowie ein kostenloses Bild zur Dateneingabe ab:
$ mkdir ~/example && cd ~/example
$ wget https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_1.0_224_quant_and_labels.zip
$ wget https://raw.githubusercontent.com/varigit/var-demos/master/machine-learning-demos/tflite/classification/media/image.jpg
Dieses Bild ist nur ein Beispiel, Sie können jedes andere Bild verwenden.
a. Extrahieren Sie das Modell in das Verzeichnis:
$ unzip mobilenet_v1_1.0_224_quant_and_labels.zipi. Entfernen Sie die überflüssigen Dateien:
$ rm -rf __MACOSX/ mobilenet_v1_1.0_224_quant_and_labels.zip2. Erstellen Sie die Datei .py , um mit dem Schreiben des Quellcodes zu beginnen:
$ touch ~/example/image_classification.py3. Die Ordnerstruktur sollte wie folgt aussehen:
.
├── image_classification.py
├── image.jpg
├── labels_mobilenet_quant_v1_224.txt
└── mobilenet_v1_1.0_224_quant.tflite
0 directories, 4 files3.1.2. Bearbeiten Sie image_classification.py und schreiben Sie den Quellcode
1. Importieren Sie zunächst die Bibliotheken Time, NumPy, Pillow und TensorFlow Lite:
1 from time import time
2
3 import numpy as np
4 from PIL import Image
5 from tflite_runtime.interpreter import Interpreter2. Öffnen und lesen Sie die Zeilen aus der Beschriftungsdatei des Klassifizierungsmodells:
6 with open('labels_mobilenet_quant_v1_224.txt') as f:
7 labels = f.read().splitlines()3. Verwenden Sie das Interpreter-Modul, um das Bildklassifizierungsmodul zu laden und dessen Tensoren zuzuordnen:
8 interpreter = tf.Interpreter(model_path="mobilenet_v1_1.0_224_quant.tflite")
9 interpreter.allocate_tensors()4. Rufen Sie die Details aus den Eingabe- und Ausgabetensoren des Bildklassifizierungsmodells ab:
10 input_details = interpreter.get_input_details()
11 output_details = interpreter.get_output_details()5. Öffnen Sie das Bild und passen Sie es entsprechend der Eingabegröße des Modells an:
12 with Image.open("image.jpg") as im:
13 _, height, width, _ = input_details[0]['shape']
14 image = im.resize((width, height))
15 image = np.expand_dims(image, axis=0)6. Stellen Sie den Eingangstensor ein, um das verkleinerte Bild als Dateneingabe in die NPU zu laden:
16 interpreter.set_tensor(input_details[0]['index'], image)7. Rufen Sie die Methode invoke auf, um die Inferenz auf der NPU zu starten:
17 interpreter.invoke() ①
18
19 start = time()
20 interpreter.invoke() ②
21 final = time()❶ Der erste Aufruf der invoke-Methode dauert aufgrund von Initialisierungsschritte länger als üblich;
❷ Um die tatsächliche Zeit der NPU für die Inferenz zu ermitteln, rufen Sie die invoke-Methode erneut auf.
Die Initialisierungsschritte werden auch als Aufwärmphase bezeichnet. Sie werden nur einmal zu Beginn der Anwendung benötigt.
8. Rufen Sie die Ausgabedetails nach Ausführung der Inferenz auf der NPU ab:
22 output_details = interpreter.get_output_details()[0]9. Ermitteln Sie die drei wichtigsten Wahrscheinlichkeiten, wie im Abschnitt 2.1.1 Überblick zur Bildklassifizierung erläutert:
23 output = np.squeeze(interpreter.get_tensor(output_details['index']))
25 results = output.argsort()[-3:][::-1]10. Drucken Sie die Beschriftungen und ihre Wahrscheinlichkeiten aus:
26 for i in results:
27 score = float(output[i] / 255.0)
28 print("[{:.2%}]: {}".format(score, labels[i]))
2911. Und schließlich drucken Sie die Inferenzzeit:
30 print("INFERENCE TIME: {:.6f} seconds".format(final-start))3.1.3 Testen Sie das Beispiel auf dem ausgewählten Modul
1. Kopieren Sie den Ordner Beispiel auf die Zielplatine:
$ scp -r ~/example root@<target-ip>:/home/root- Führen Sie auf der Platine folgende Befehle aus:
# cd /home/root/example
# python3 image_classification.py-
-
- Das Ergebnis einer erfolgreichen Klassifizierung sollte in etwa wie folgt aussehen:
-
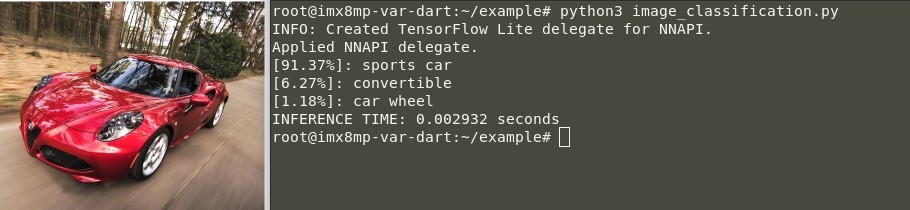
Abbildung 3. Eingabebeispiel für die Bildklassifizierung mit TensorFlow Lite (NPU-Inferenz)
🕒 Inferenzzeit auf NPU: 2,9 Millisekunden.
Wie Sie sehen können, hat das Modell eine hohe Wahrscheinlichkeit (91,37%) vorhergesagt, dass das Bild einen Sportwagen darstellt.
Dieses Beispiel kann als Grundlage für jede Anwendung im Zusammenhang mit Bildklassifizierungsproblemen verwendet werden. Sie können beispielsweise den Quellcode so ändern, dass eine Videodatei oder ein Live-Videostream von einer Kamera statt einer Bilddatei verwendet wird. Dazu verwenden Sie OpenCV und GStreamer, wie im oben erwähnten var-demos Repository angegeben.